Summarize clustering characteristics and estimate the best number of clusters for a data set.
Introduction
This article only requires the tidymodels package.
K-means clustering serves as a useful example of applying tidy data principles to statistical analysis, and especially the distinction between the three tidying functions:
Let’s start by generating some random two-dimensional data with three clusters. Data in each cluster will come from a multivariate gaussian distribution, with different means for each cluster:
library(tidymodels)set.seed(27)centers<-tibble( cluster =factor(1:3), num_points =c(100, 150, 50), # number points in each cluster x1 =c(5, 0, -3), # x1 coordinate of cluster center x2 =c(-1, 1, -2)# x2 coordinate of cluster center)labelled_points<-centers|>mutate( x1 =map2(num_points, x1, rnorm), x2 =map2(num_points, x2, rnorm))|>select(-num_points)|>unnest(cols =c(x1, x2))ggplot(labelled_points, aes(x1, x2, color =cluster))+geom_point(alpha =0.3)
This is an ideal case for k-means clustering.
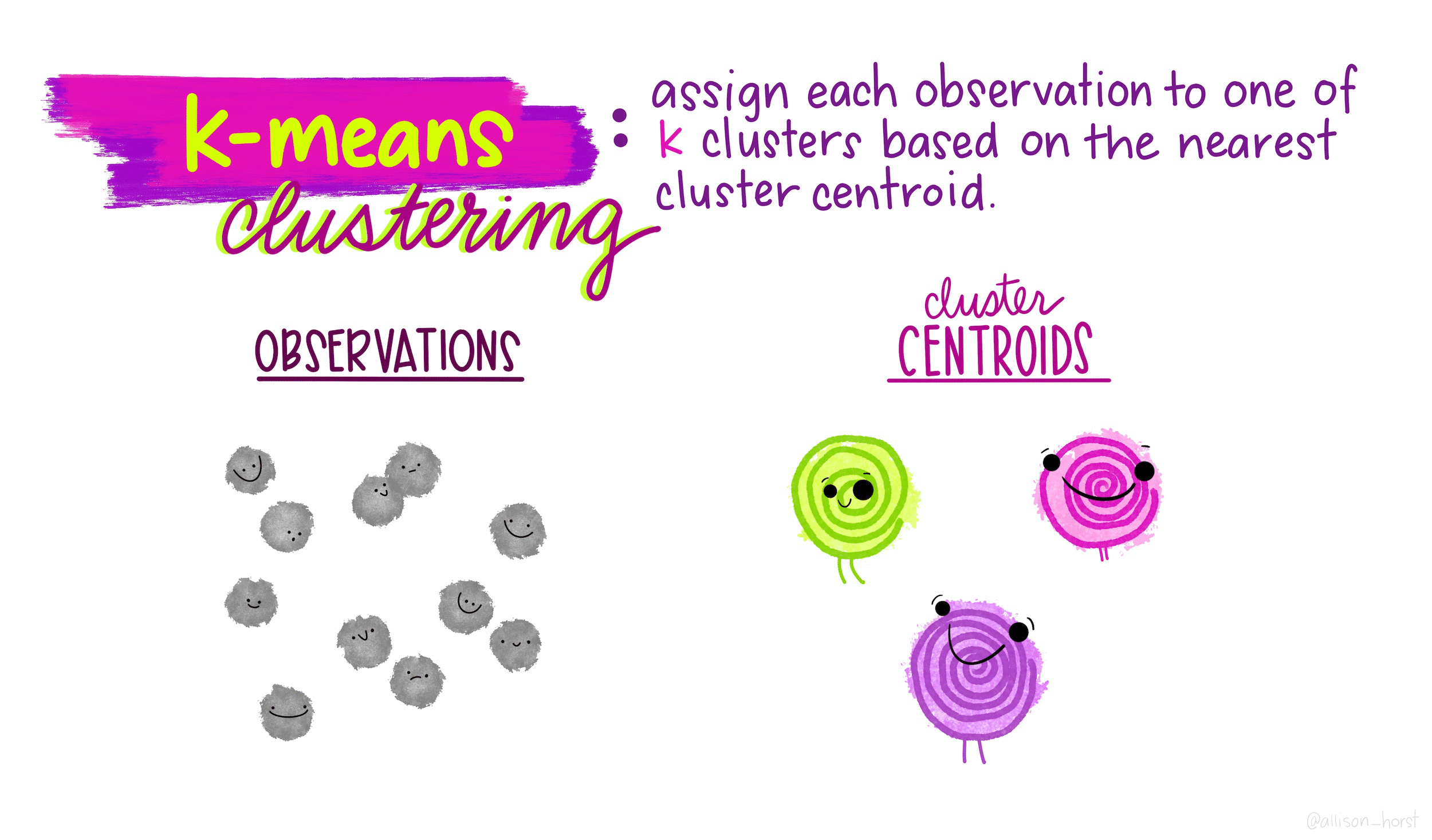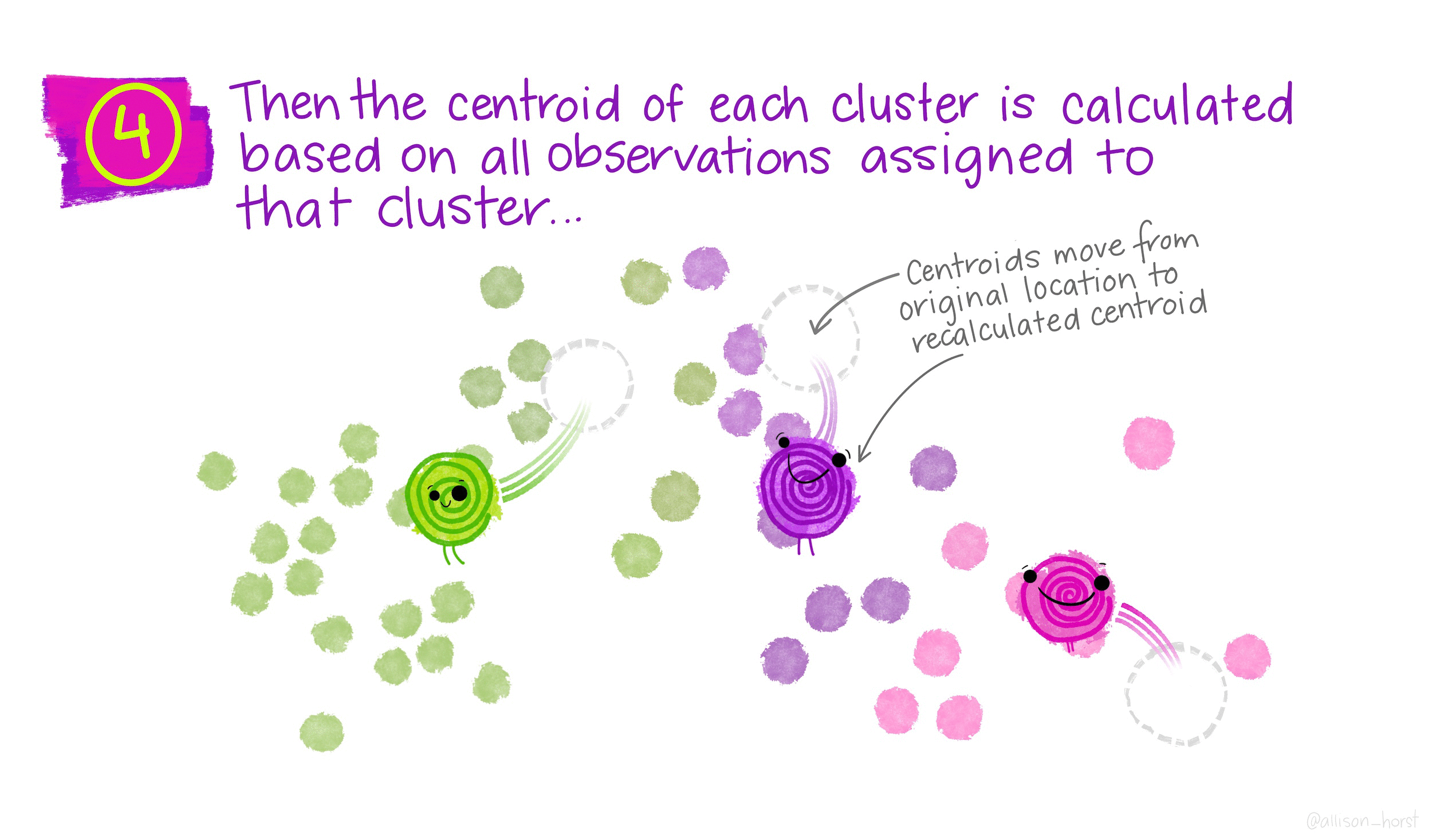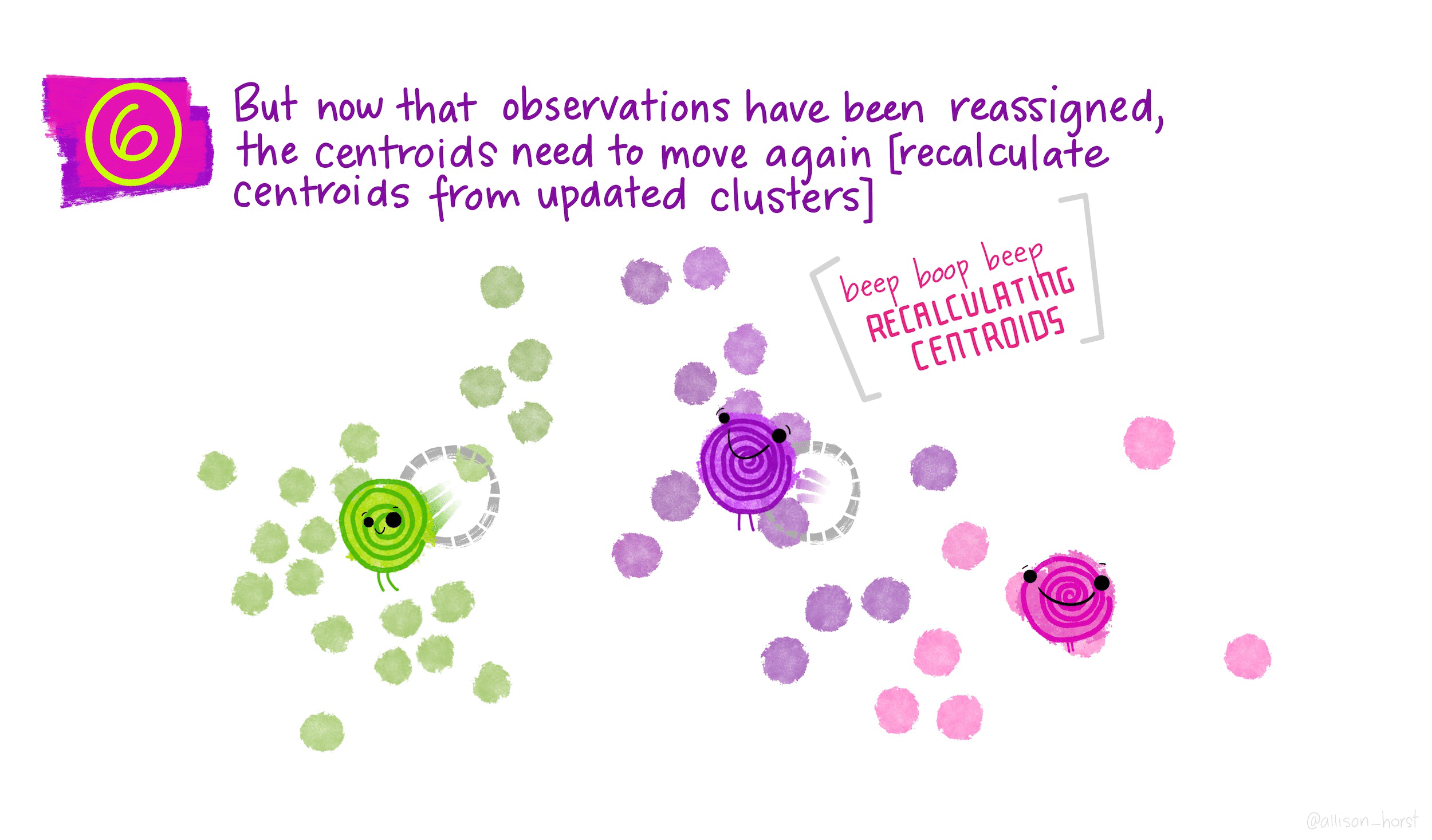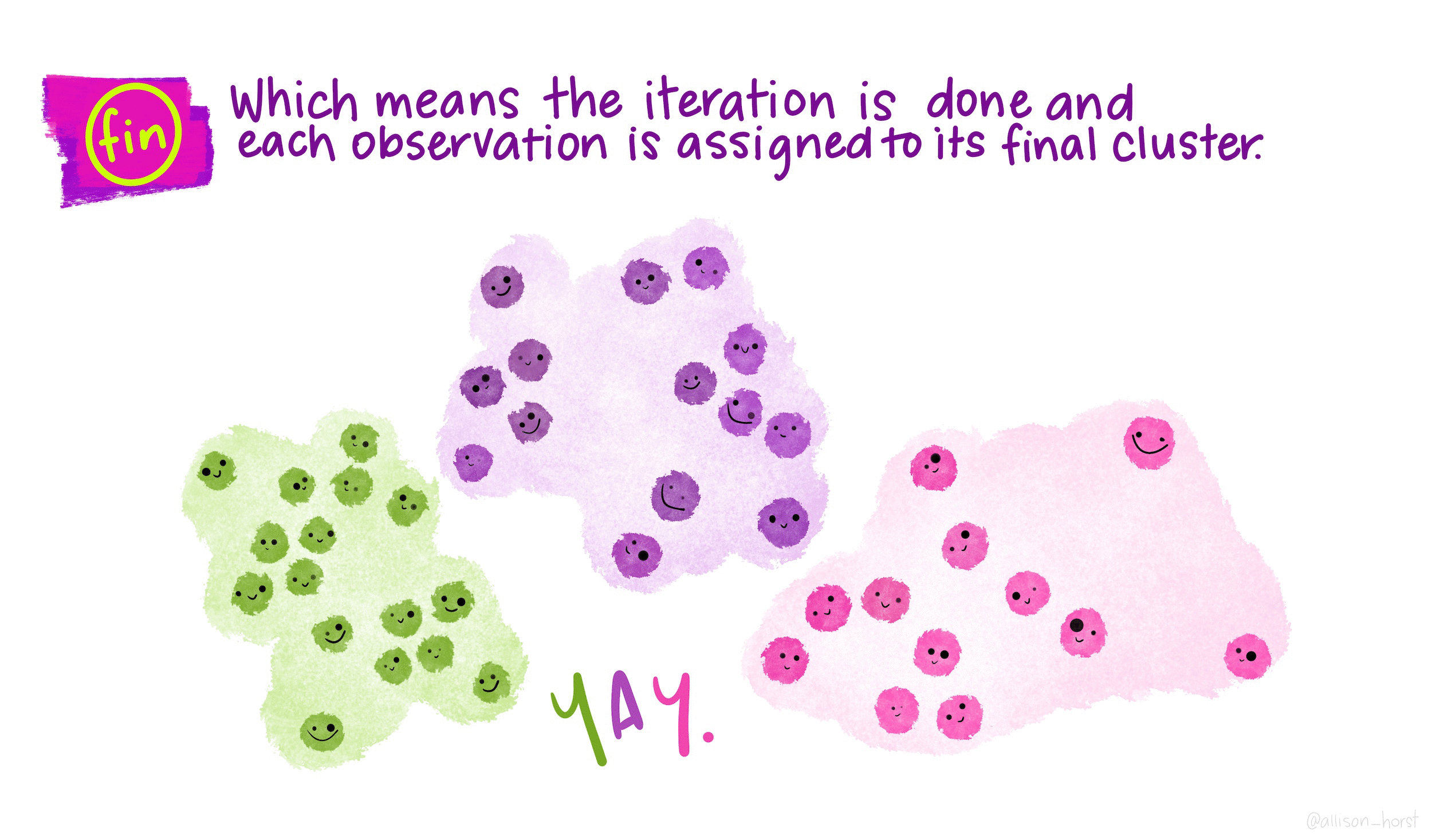
How does K-means work?
Rather than using equations, this short animation using the artwork of Allison Horst explains the clustering process:
Clustering in R
We’ll use the built-in kmeans() function, which accepts a data frame with all numeric columns as it’s primary argument.
The output is a list of vectors, where each component has a different length. There’s one of length 300, the same as our original data set. There are two elements of length 3 (withinss and tot.withinss) and centers is a matrix with 3 rows. And then there are the elements of length 1: totss, tot.withinss, betweenss, and iter. (The value ifault indicates possible algorithm problems.)
These differing lengths have important meaning when we want to tidy our data set; they signify that each type of component communicates a different kind of information.
cluster (300 values) contains information about each point
centers, withinss, and size (3 values) contain information about each cluster
totss, tot.withinss, betweenss, and iter (1 value) contain information about the full clustering
Which of these do we want to extract? There is no right answer; each of them may be interesting to an analyst. Because they communicate entirely different information (not to mention there’s no straightforward way to combine them), they are extracted by separate functions. augment adds the point classifications to the original data set:
While these summaries are useful, they would not have been too difficult to extract out from the data set yourself. The real power comes from combining these analyses with other tools like dplyr.
Let’s say we want to explore the effect of different choices of k, from 1 to 9, on this clustering. First cluster the data 9 times, each using a different value of k, then create columns containing the tidied, glanced and augmented data:
We can turn these into three separate data sets each representing a different type of data: using tidy(), using augment(), and using glance(). Each of these goes into a separate data set as they represent different types of data.
Already we get a good sense of the proper number of clusters (3), and how the k-means algorithm functions when k is too high or too low. We can then add the centers of the cluster using the data from tidy():
The data from glance() fills a different but equally important purpose; it lets us view trends of some summary statistics across values of k. Of particular interest is the total within sum of squares, saved in the tot.withinss column.
This represents the variance within the clusters. It decreases as k increases, but notice a bend (or “elbow”) around k = 3. This bend indicates that additional clusters beyond the third have little value. (See here for a more mathematically rigorous interpretation and implementation of this method). Thus, all three methods of tidying data provided by broom are useful for summarizing clustering output.